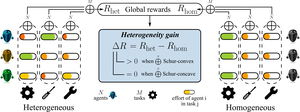
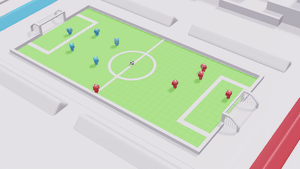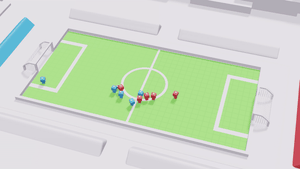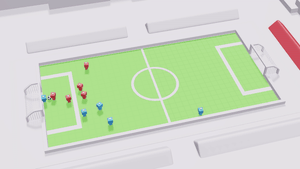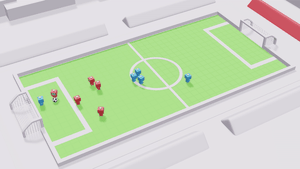
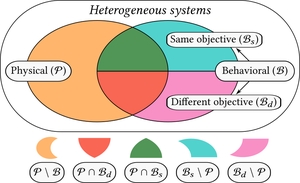
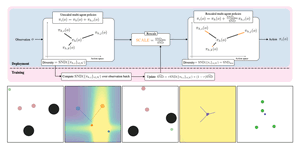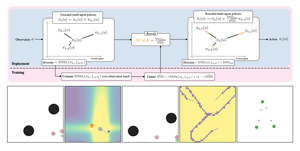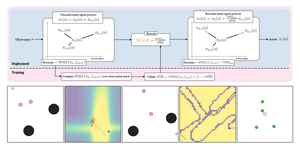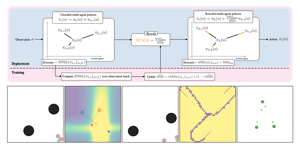
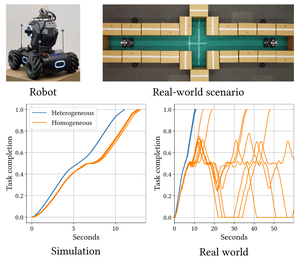
This thesis presents a study of neural diversity in multi-agent systems, demonstrating its key, though previously ignored, role in collective learning. We introduce novel methods to simulate, enable, train, measure, and control neural diversity in multi-agent reinforcement learning. The results gathered show that neural diversity is fundamental for cooperation, exploration, and resilience, paving the way towards the understanding and development of collective artificial general intelligence.