VMAS: A Vectorized Multi-Agent Simulator for Collective Robot Learning
Abstract
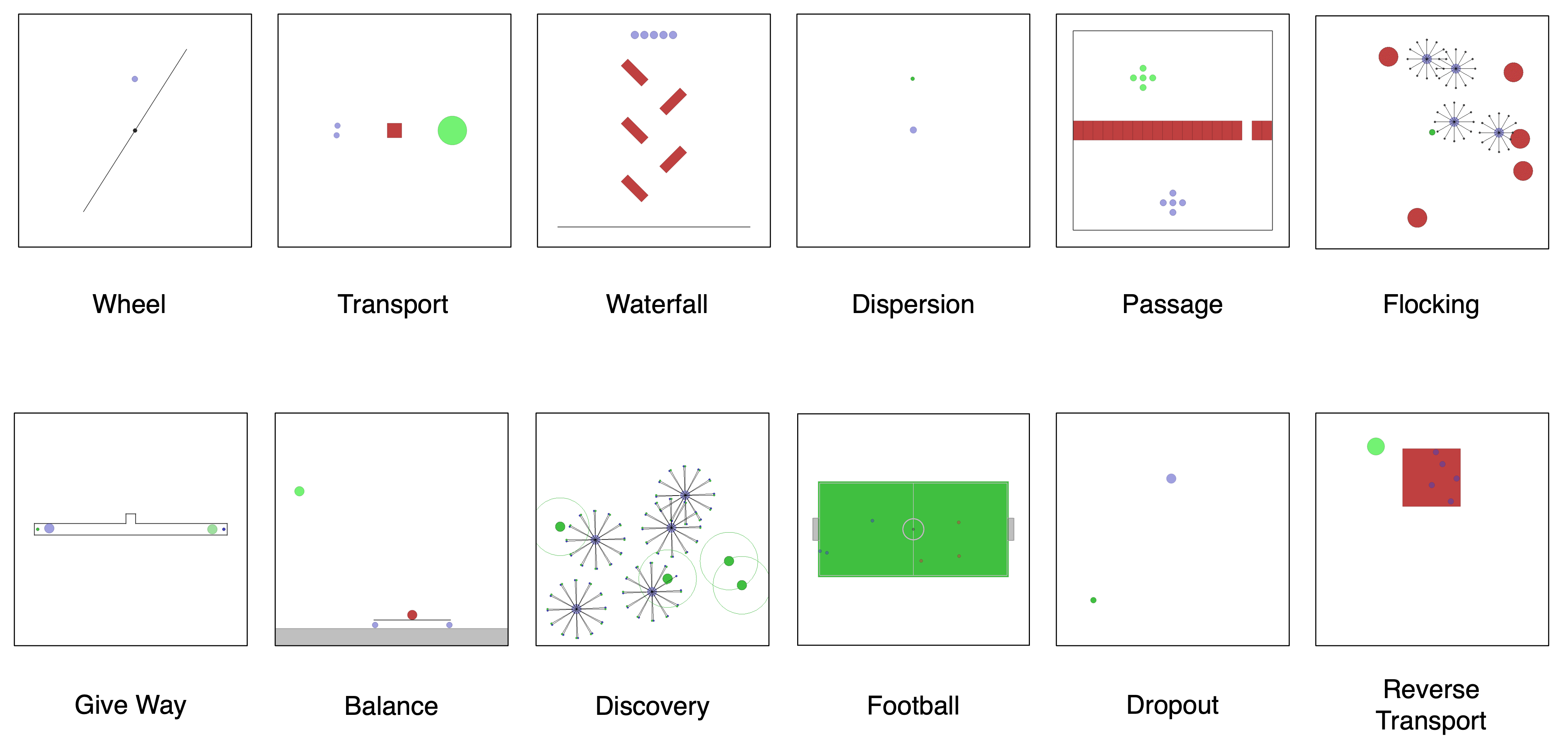
While many multi-robot coordination problems can be solved optimally by exact algorithms, solutions are often not scalable in the number of robots. Multi-Agent Reinforcement Learning (MARL) is gaining increasing attention in the robotics community as a promising solution to tackle such problems. Nevertheless, we still lack the tools that allow us to quickly and efficiently find solutions to large-scale collective learning tasks. In this work, we introduce the Vectorized Multi-Agent Simulator (VMAS). VMAS is an open-source framework designed for efficient MARL benchmarking. It comprises a vectorized 2D physics engine written in PyTorch and a set of twelve challenging multi-robot scenarios. Additional scenarios can be implemented through a simple and modular interface. We demonstrate how vectorization enables parallel simulation on accelerated hardware without added complexity. When comparing VMAS to OpenAI MPE, we show how MPE’s execution time increases linearly in the number of simulations while VMAS is able to execute 30,000 parallel simulations in under 10s, proving more than 100x faster. Using VMAS’s RLlib interface, we benchmark our multi-robot scenarios using various Proximal Policy Optimization (PPO)-based MARL algorithms. VMAS’s scenarios prove challenging in orthogonal ways for state-of-the-art MARL algorithms.
Scenarios
Video
Matteo Bettini
Researcher
Matteo’s research is focused on multi-agent reinforcement learning, with applications to robotics and LLM agents.
Ryan Kortvelesy
PhD Candidate
Ryan’s work focuses on multi-agent reinforcement learning. He is interested in the credit assignment problem, new graph neural network architectures and explainability (applying symbolic regression to multi-agent systems).
Jan Blumenkamp
PhD Candidate
Jan’s research is about transferring Multi-Agent control policies trained in simulation to the real world (sim-to-real transfer), using Multi-Agent Reinforcement Learning and Graph Neural Networks. He is also interested in interpretability, resilience and robustness of such control policies, particularly in the context of real-world systems.
Amanda Prorok
Professor
Amanda’s research focuses on multi-agent and multi-robot systems. Our mission is to find new ways of coordinating artificially intelligent agents (e.g., robots, vehicles, machines) to achieve common goals in shared physical and virtual spaces.