BenchMARL: Benchmarking Multi-Agent Reinforcement Learning
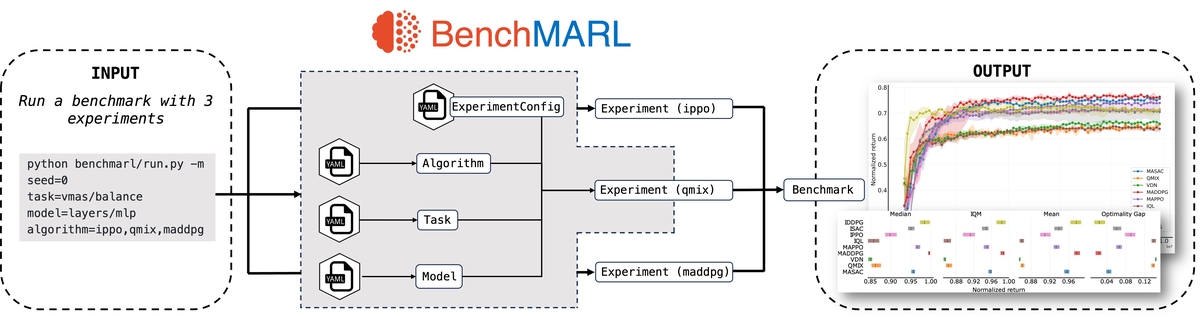 BenchMARL execution diagram
BenchMARL execution diagramAbstract
The field of Multi-Agent Reinforcement Learning (MARL) is currently facing a reproducibility crisis. While solutions for standardized reporting have been proposed to address the issue, we still lack a benchmarking tool that enables standardization and reproducibility, while leveraging cutting-edge Reinforcement Learning (RL) implementations. In this paper, we introduce BenchMARL, the first MARL training library created to enable standardized benchmarking across different algorithms, models, and environments. BenchMARL uses TorchRL as its backend, granting it high performance and maintained state-of-the-art implementations while addressing the broad community of MARL PyTorch users. Its design enables systematic configuration and reporting, thus allowing users to create and run complex benchmarks from simple one-line inputs.
Matteo Bettini
Researcher
Matteo’s research is focused on multi-agent reinforcement learning, with applications to robotics and LLM agents.
Amanda Prorok
Professor
Amanda’s research focuses on multi-agent and multi-robot systems. Our mission is to find new ways of coordinating artificially intelligent agents (e.g., robots, vehicles, machines) to achieve common goals in shared physical and virtual spaces.